单元测试上瘾
nisp重构启动,python服务器端初步完成,node客户端也需要同步重构。
受益于python中的单元测试用例的覆盖,发现了不少之前没有发现的问题,于是乎node也要高高单元测试才行 >_<
参考“Comparing the best Node.js unit testing frameworks”,挑选了Mocha和Jest试了下,最后选择Jest,比较好上手,而且自带覆盖度评估。
nisp重构启动,python服务器端初步完成,node客户端也需要同步重构。
受益于python中的单元测试用例的覆盖,发现了不少之前没有发现的问题,于是乎node也要高高单元测试才行 >_<
参考“Comparing the best Node.js unit testing frameworks”,挑选了Mocha和Jest试了下,最后选择Jest,比较好上手,而且自带覆盖度评估。
昨天跟同事讨论“某基金持有1年的时间的盈利(不亏本)的概率是多少”这个问题。
我同事的算法是:
我昨天建议改用正态分布的方式去做(前面两点假设一样):
昨天我认为我同事的算法不是在计算概率,而更多算的是一种频度;今天早上想起了泊松分布,在想是否可以用其他的分布来去解释这个所谓的“盈利概率”,最后得到了如下的答案:
其实都没有错!
第二次读这本书了(第一次读是纸质版,第二次是微信读书上看的),当读到这一段时:

想到了“如何把Z Score转换为P值”这个疑问。于是,回顾了下:
对于正态分布$\mathcal{N}(\mu, \sigma)$,其概率密度函数为:
$$ PDF = \frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2} = \frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{z^2}{2}} $$
其累积分布函数为:
$$ CDF = \Phi(x) = P(Z \leq x) = \frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{x}e^{-\frac{t^2}{2}}dt $$
考虑到误差函数(Error Function)
$$ erf(x) = \frac{2}{\sqrt{\pi}}\int_{0}^{x}e^{-t^2}dt $$
可以将累积分布函数采用erf来进行计算,即有:
$$ CDF = \frac{1}{2}\big[1+erf(\frac{x-\mu}{\sigma\sqrt{2}})\big] = \frac{1}{2}\big[1+erf(\frac{z}{\sqrt{2}})\big] $$
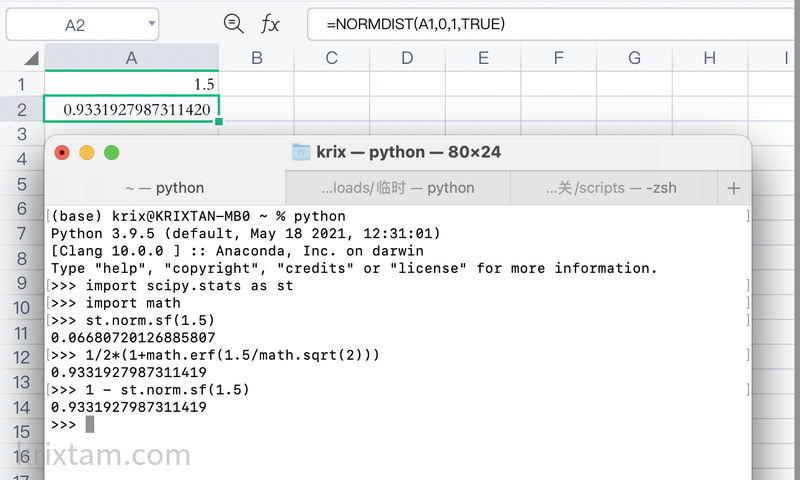
Excel或者是WPS下相关的公式是NORMDIST,在Python中可以用scipy.stats.norm.sf。
比如要计算书中例子,投资回报率15%,年误差率10%,那么任何一年赚钱的概率93%,可以这样计算:
最后,因为好奇心下,又去找了下实现,比如:
发现了Netlib这个好地方,如果可以快速索引的话,可能里头很多方法的源码实现都可以好好研究下
MATLAB的erf是基于”Rational Chebyshev Approximations for Error Function –W.J.Cody”实现的,可以参考这里
实际上,用近似实现可以简化,误差方面,也还是可以接受,试了一下:
我在本地也存了一份
Python写了这4个算法的测试,可以从这里下载源文件
读《思考,快与慢》时遇到“前景理论”,于是乎搜索了一下并把一些收获记录下来。
前景理论(prospect theory):人在不确定条件下的决策选择,取决于结果与展望(预期、设想)的差距而非單單结果本身。即,人在决策时会在心里预设一个参考标准,然后衡量每個決定的结果,与这个参考标准的差别是多大。
该理论将决策过程描述为两个阶段:
以上为翻译,原文如下:
The theory describes the decision processes in two stages:
During an initial phase termed editing, outcomes of a decision are ordered according to a certain heuristic. In particular, people decide which outcomes they consider equivalent, set a reference point and then consider lesser outcomes as losses and greater ones as gains. The editing phase aims to alleviate any framing effects. It also aims to resolve isolation effects stemming from individuals’ propensity to often isolate consecutive probabilities instead of treating them together. The editing process can be viewed as composed of coding, combination, segregation, cancellation, simplification and detection of dominance.
In the subsequent evaluation phase, people behave as if they would compute a value (utility), based on the potential outcomes and their respective probabilities, and then choose the alternative having a higher utility.
评估阶段的价值函数可以表达为:
$$ V = \sum_{i=1}^{n}\pi(p_i)v(x_i) $$
通过参考点的价值函数是S形的,不对称的。损失的价值函数比收益更陡峭,表明损失大于收益。
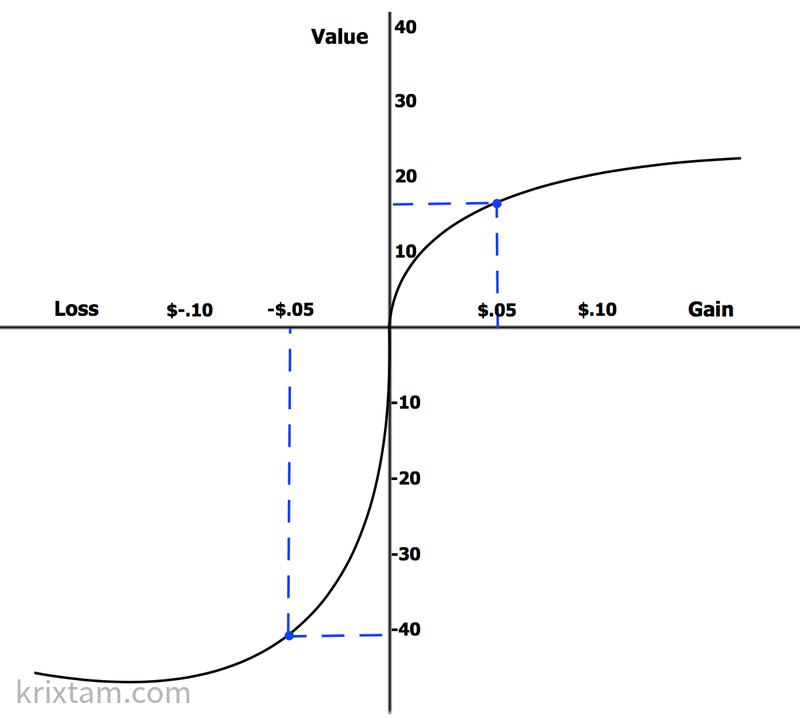
此理论引申的四个基本結論
以上四个基本结论摘自Wikipedia
换一种说法:
人類傾向於喜歡自己擁有的東西,當我們產生擁有一件東西的感覺後,該東西的價值也會在我們心中相應地提升。
在遊戲相關提供客製化的服務,讓玩家自行組裝自己的人物或是世界,藉由獲得個人的獨特經驗,讓玩家更加沉浸於遊戲中。
基于这个效应,可以更深刻了解到马基雅维利说的:
惩罚必需一次给足,赏赐则要一点一点给予。